Video generative models have emerged as a promising robotics backbone, capable of generating
videos that depict the completion of complex tasks across embodiments and environments. Many
current approaches finetune video models with action-labeled data, turning them into robot
foundation models that jointly predict future observations and actions.
In this paper, we study an alternative, underexplored route for transferring the capabilities
of video models into robot control: leave the video planner as is, while training an
embodiment-specific inverse dynamics model (IDM). This decoupling offers several
advantages: the video planner can remain embodiment-agnostic; different video models can be
interchanged easily without re-training the IDMs; and the inverse dynamics model can be
trained with the more readily available autonomous self-play data.
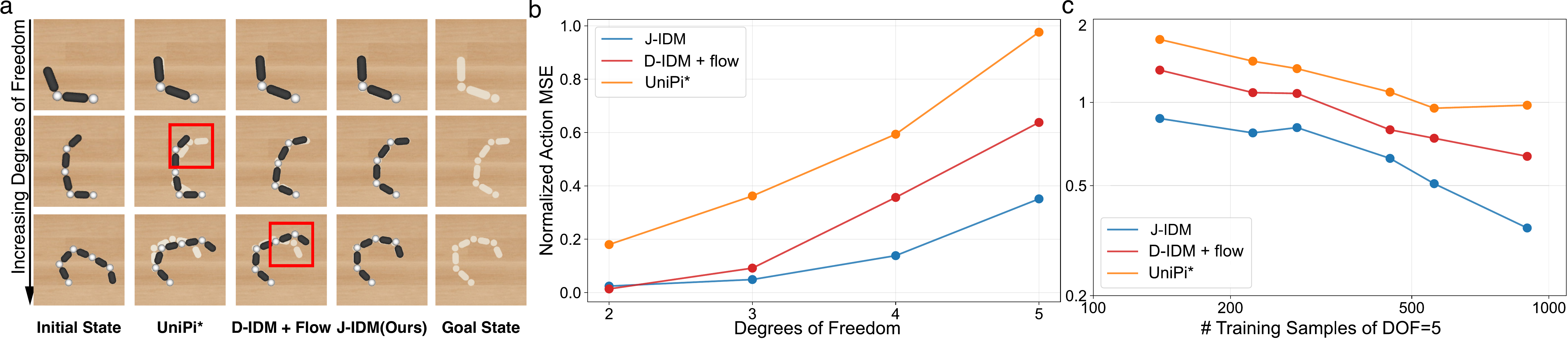
With this in mind, we present a closed-loop, video-to-action policy that combines an
action-free video world model with a carefully designed IDM based on the robot embodiment
Jacobian. We find that such a structure yields a faithful video-to-action
translator that is both data-efficient and scalable to high-dimensional action spaces. Our
policy, which we coin the Video–Jacobian–Action Model (VJAM),
achieves strong performance across simulated and real-world benchmarks, including zero-shot
Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation. The same video
planner can be used across multiple embodiments by pairing it with different
embodiment-specific IDMs.
Our results show that decoupled video planning plus faithful video-to-action translation is a
viable alternative route towards zero-shot, cross-embodiment, and generalizable robot control.